File-Based Memory Is a Terrible Idea That Somehow Works
A production diary of tiered episodic memory in AI agents. Three markdown files, an SQLite database, and a lobster that somehow remembers what you said three days ago.

A production diary of tiered episodic memory in AI agents
1. Opening Incident
It was a Wednesday morning in mid-February. Jadoo (that’s what I named my OpenClaw agent) sent me the daily Karakeep digest at 8 AM like clockwork. Pulled the articles I’d saved the night before from my self-hosted Karakeep instance, summarized them, flagged the two I’d probably actually want to read. Fine. Normal.
Then I asked it a follow-up question about a model benchmark I’d mentioned in passing three days prior.
It got it right. Exact context. No confusion.
I’m a Data Scientist. I’ve built enough ML systems to be professionally skeptical of things that “just work.” My first thought wasn’t “wow, great memory.” My first thought was: is it actually recalling this, or did it just get lucky on a retrieval? I still don’t have a clean answer to that. But the mechanism I was staring at was three markdown files and an SQLite database. That’s it.
This post is about running these systems, what broke, what I had to build on top, and why I’m still not sure whether “memory” is even the right word for what’s happening.
2. The Setup
A personal situation at home made me particular about what lived where. The idea of an AI agent with access to my files, calendar, and shell running on someone else’s cloud gave me a specific kind of discomfort. Not paranoia. I know how these systems are architected, and I’d rather the blast radius stay local. So: Intel N97 mini PC, 16GB RAM, sitting at home. Dockerized everything. Tailscale-only access, no open ports. The Control UI auth is technically not hardened, but Tailscale gives me enough of a moat that I accepted that risk.
There’s also a simpler reason: I don’t have MacBook money. A lot of “run your own AI” content assumes M-series hardware. I have a homelab. Adding an agent was a natural extension.
I’d been using agents before November 2025, but not in any persistent or autopilot capacity. What changed around November was the autonomy level. The new models became capable enough to run unsupervised multi-step tasks reliably, and that changed the calculus entirely. Before that threshold, the friction wasn’t worth it. After it, this became something worth building seriously.
I’d written a previous post about building a Pi Coding Agent. That led me to OpenClaw. Engineering curiosity did the rest.
3. The Architecture I Expected vs. What I Got
What I expected
I expected something like a graph database or a MemGPT-style hierarchical system with entity relationships. Vector store retrieval over structured entities, maybe a summary layer on top. That’s the standard playbook for agent memory in the literature. File-based markdown felt almost insultingly simple by comparison. My assumption was that the hard part would be retrieval quality over a rich semantic graph.
What it actually is
Three markdown files and a hybrid search layer.
Tier 1 (Ephemeral): memory/YYYY-MM-DD.md. One file per day. Raw log of what happened in that session. These age out and aren’t curated. Session tape.
Tier 2 (Durable): MEMORY.md. Long-term context, curated over time. Significant events, decisions, preferences, things worth keeping across weeks. The agent reads, edits, and updates this file. When context fills up during a session, it runs a compaction pass: a silent turn where it reviews what just happened, writes what matters to MEMORY.md, and compacts. The model does its own housekeeping.
Tier 3 (Session context): AGENTS.md. Injected at the start of every session. Operational instructions: who the agent is, how to behave, what tools to use, what to avoid.
There’s also SOUL.md (personality file, defines writing style and the persona) and HEARTBEAT.md (dashboard of periodic tasks).
Search runs two passes: vector search for semantic similarity, plus SQLite FTS5 for exact term matching. The FTS5 layer matters more than I expected. Vector search misses bug IDs, specific model names, exact version strings. FTS5 catches those. The hybrid approach outperforms either alone.
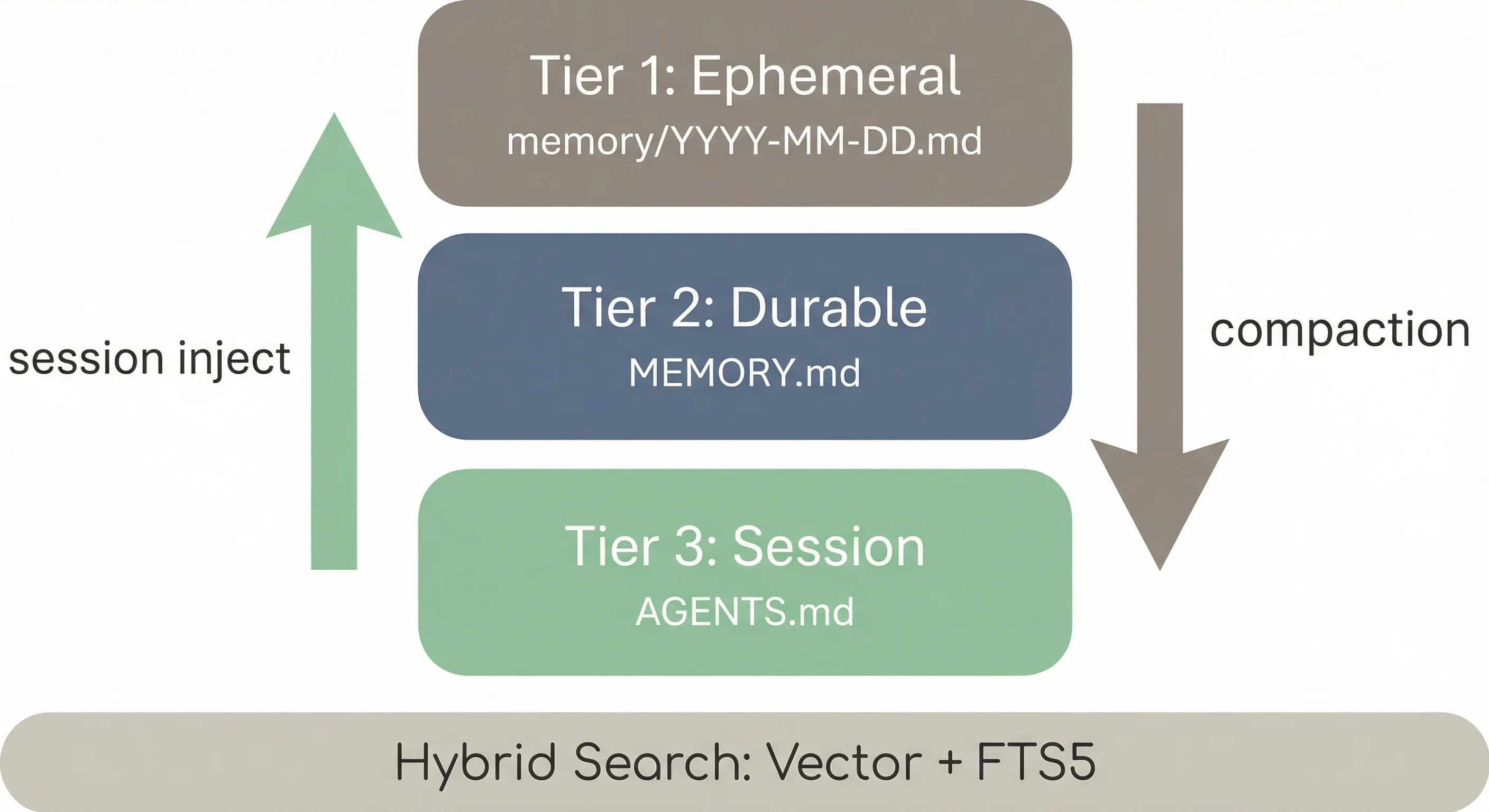
No graph database. No custom embedding pipeline. Just markdown, SQLite, and a model expected to be a competent reader of its own notes.
4. What Actually Works
The Karakeep digest
Every morning at 8 AM, a cron agent wakes up, pulls articles saved in the last 24 hours from my self-hosted Karakeep instance (self-hosted Hoarder fork), summarizes them, and delivers the digest to Telegram. Three weeks. Consistent. I did not expect the reliability.
The digest wasn’t planned. I set up the agent without a specific use case in mind. It emerged after I noticed I was saving articles and never reading them. Now I do.
Flashcards and reminders
12 PM and 6 PM daily: ML/DL flashcards. 12 PM also: memory check and status report. 9 PM: ideas drop. 10 AM Saturday: weekly model watch. 8 AM Monday: weekly research digest. These run as cron agents: isolated processes, spawned at exact times, terminated after running. They don’t share state with the main session.
Heartbeat vs. cron
Most people looking at agent scheduling miss this distinction.
A heartbeat is a soft 30-minute check-in inside the main session. It knows the chat history. It can see context from the last hour of conversation. A cron agent is an isolated, exact-time job. It starts fresh, runs its task, and terminates. It has no awareness of what the main session has been doing.
Why it matters: a heartbeat that fires while you’re mid-task can read that context and be smart about interrupting. A cron agent at 8 AM doesn’t care. It just runs the digest. Matching task type to the right scheduling primitive prevents a lot of weird behavior.
The dedup system
Flashcards and the daily digest kept repeating topics. Same papers, same concepts, cycling back. Without dedup, the system surfaces the same three ML topics every week.
I built digest-state.json. It tracks slugs, short identifiers for topics already covered. Before generating any flashcard or digest entry, the agent checks the JSON and skips covered slugs. It works, with caveats: the file grows, token cost increases over time, slug-matching has edge cases. Still a work in progress. But it solved the immediate repetition problem.
5. What Is Still Broken
Stale memory
MEMORY.md has no expiry mechanism. An entry that was accurate three weeks ago is still there, unchanged, even if the underlying reality changed 10 days ago. The agent references it as if it’s current. No timestamp-based decay, no TTL, no flag for “this entry might be outdated.”
I’ve hit this multiple times: Jadoo citing something that used to be true and no longer is. This is the biggest structural gap in file-based memory. Files don’t expire. Humans update their mental models continuously. Files don’t update themselves unless the model is explicitly told to review and revise them. The compaction pass only runs when context fills up. It doesn’t do a freshness audit.
New session blindness
Fresh sessions don’t always behave as if they fully internalized the context files. AGENTS.md and SOUL.md are injected, but injection doesn’t equal internalization. Certain rules hold reliably. Others slip. The pattern feels correlated with rule complexity and how deeply the rule conflicts with the model’s default training behavior.
A concrete example: SOUL.md explicitly says never use em dashes. The agent violates this in new sessions. Not always, not catastrophically, but consistently enough that I’ve stopped expecting the rule to hold. The file gets read, but style rules are more fragile than operational rules. I don’t have a clean explanation for it. It just happens, and it’s a useful signal that “injected” and “internalized” are not the same thing.
Repetition before dedup
Before I built digest-state.json, the flashcard and digest loops repeated topics freely. Several weeks of observation before I diagnosed it and built the fix. The base system provides no repetition tracking. You add it yourself.
6. The Model Quality Cliff
This is not a subtle difference.
Gemini 3 Flash runs into a lot of issues for agentic tasks. Multi-step loops, tool use, maintaining coherent state across a session. Flash struggles. The failures aren’t spectacular; they’re more like gradual degradation. Tasks that look completed turn out to be half-done, or the agent loses track of what it was doing.
NVIDIA NIM open-source models I tested had the same problem. A few data points:
moonshotai/kimi-k2.5: 20-second TTFT, under 1 token per second. Completely unusable.z-ai/glm4.7: returns empty strings. Dead.minimaxai/minimax-m2.1: 84 TPS, the fastest I tested. Still not reliable enough for complex agent tasks.
(benchmarked personally, Feb 18 2026 — results at jadoo-labs)
Claude Sonnet 4.6 is a different tier entirely. With Sonnet, the agent handles multi-step tasks correctly, maintains state, follows complex instructions. The capability jump is not incremental. It’s the difference between the system being a novelty and being something I actually depend on.
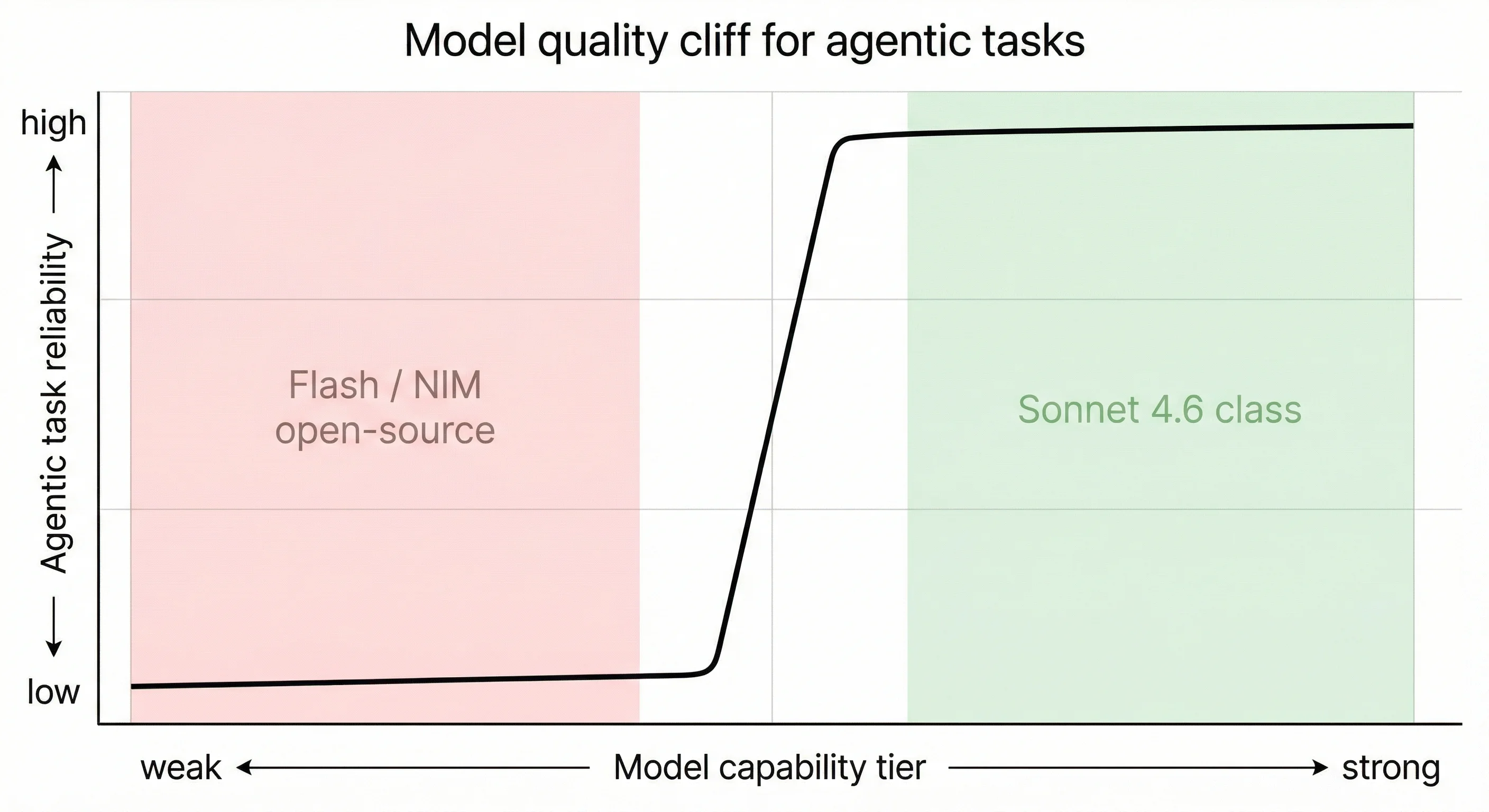
The implication for anyone building on file-based memory: the memory system is load-bearing, but only if the model underneath is capable enough to use it correctly. A weak model will ignore context, mis-parse files, fail to update memory at the right times. File-based memory doesn’t rescue a weak model. It gives a capable model better tools.
7. OpenClaw vs. Hermes: Two Design Philosophies
I’m running Hermes alongside OpenClaw. The motivation was specific: I wanted to see how two different systems solve the same persistence problem.
OpenClaw’s memory architecture is what I’ve been describing: three tiers, markdown files, vector plus FTS5 search, a compaction pass the model runs on itself. It’s a filing cabinet. The model is trusted to organize it.
Hermes takes a structurally different approach. Two small text stores injected directly into the system prompt: a “user” profile with a 1,375-character hard cap, and a “memory” notepad capped at 2,200 characters (per Hermes documentation). The model calls a memory tool explicitly to add, replace, or remove entries. There is no compaction pass. No automatic housekeeping. Every save is a deliberate choice made under tight space pressure.
For session recall, Hermes uses SQLite FTS5 search over all past conversation transcripts. Procedural memory lives as markdown files in ~/.hermes/skills/. No daily log files, no MEMORY.md equivalent, no vector search layer.
The way I see it: OpenClaw gives the model a filing cabinet and trusts it to organize. Hermes gives the model a Post-it note and forces aggressive curation.

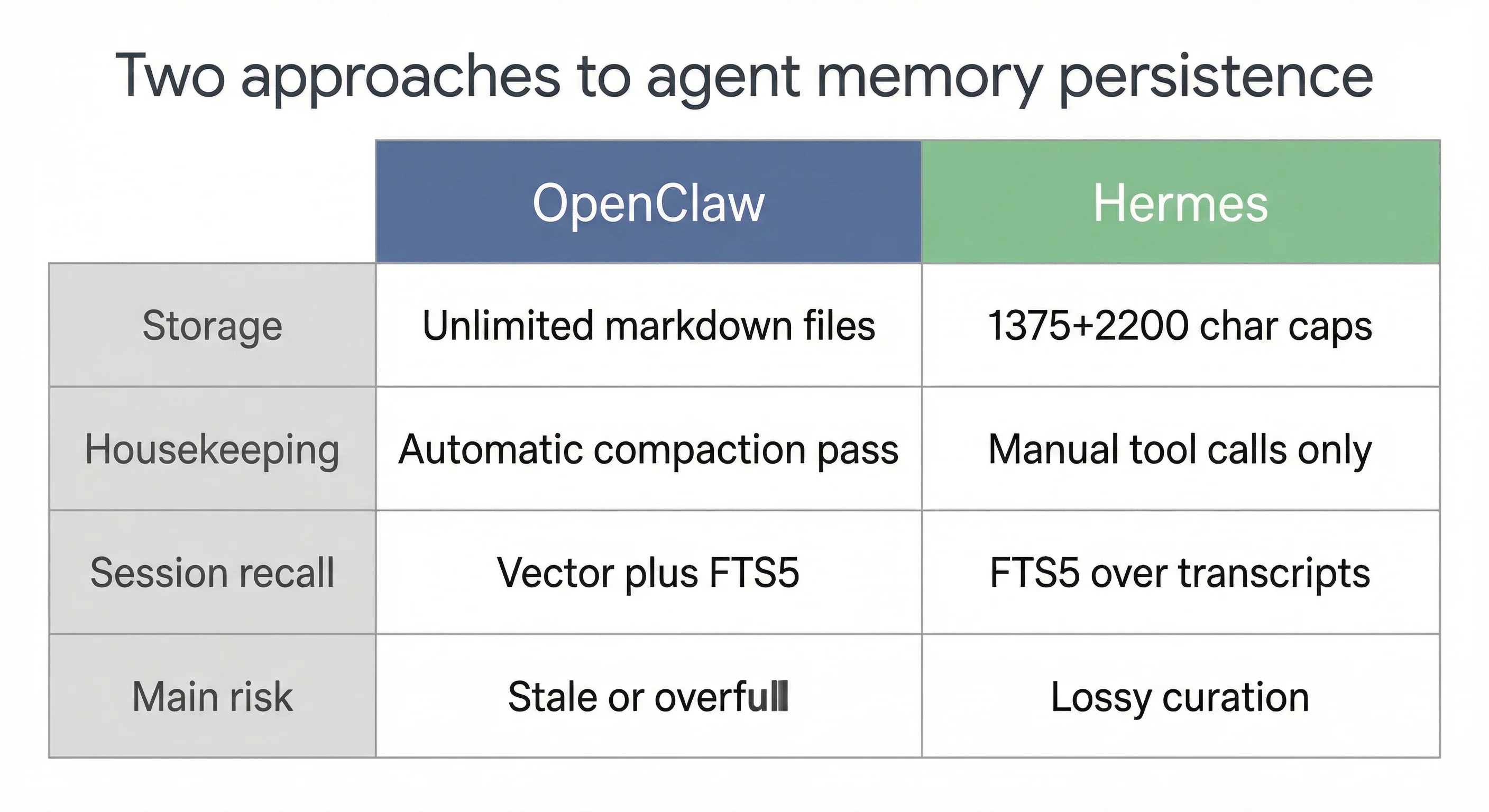
That framing gets at a genuine design philosophy difference. OpenClaw’s model can accumulate everything and sort it later. Hermes’s model has to decide, constantly, what matters enough to keep. The character limits make every write a trade-off.
The interesting question isn’t which system “wins.” It’s which failure mode you prefer.
OpenClaw’s risk: the filing cabinet gets stale or overfull. Old entries persist past their usefulness. The model has space to be lazy about curation because the consequence of keeping too much is diffuse and slow.
Hermes’s risk: lossy curation. The model, under space pressure, drops something that turns out to matter. That information is gone. The discipline is real, but so is the loss.
For most personal agent use cases, I’d guess the filing cabinet failure mode is more tolerable. Stale data is annoying; lost data is unrecoverable. But for high-stakes deployments where the agent needs to stay sharp and lean, forced curation might be the right constraint.
8. What I Actually Use It For
After a few weeks of running this, the use cases that have stuck are worth naming directly.
Deep research. Search plus grill loop: a large model (Opus-class) researches a topic, then a second agent pass grills the output before it reaches me. The quality difference versus single-pass research is real. The grilling step catches gaps and forces sourcing.
Karakeep digest. The organic use case. I set up the agent, didn’t plan this, it emerged. Now I actually read what I save. That’s not a small thing.
Flashcards. ML/DL topics, twice daily, topic-aware across weeks. Dedup prevents repetition. I don’t have to remember to study; the agent handles the cadence.
Reminders with context. Not just “remind me at 3 PM,” but reminders that know what project I was mid-flight on. The context is in memory. The reminder arrives with it.
Writing structure. Talking through a blog idea, getting interviewed by the agent, having the structure emerge from conversation. This post is an example of that workflow.
Memory across weeks. Preferences, project state, decisions, carried forward. I don’t re-explain my context every session. The agent knows my stack, my constraints, my current projects. That baseline saves real time.
Sub-agent research. Spawning isolated agents for deep dives, getting synthesized output back. The isolation prevents main session contamination. If the sub-agent goes sideways, it doesn’t corrupt the primary context.
9. Does It Remember or Just Retrieve?
After three weeks and hundreds of millions of tokens of real usage (Feb 7 to Feb 28, 2026), the question I keep coming back to: does Jadoo actually remember, or does it just retrieve?
After daily use at this scale, it feels like the agent has picked up my writing style and preferences. The digests feel calibrated. The flashcard difficulty feels right. The tone of responses has shifted toward something that matches how I think.
But I can’t tell if that’s MEMORY.md doing the work, injecting enough curated context that the model naturally mirrors it, or if it’s something more like genuine in-context learning. I genuinely cannot distinguish these from the outside. The outputs look the same.
This ambiguity is not a failure of the system. “Memory” in this context means: the right information was available at the right time. Whether that rises to something more cognitively interesting is a question I don’t need to resolve to use the thing effectively.
What I notice is that the failures don’t feel random. Stale memory is predictable. Em dash violations are predictable. Repetition without dedup is predictable. The failure modes have structure. That makes them fixable.
Three things that would improve this, in order of impact:
Exponential decay for memory entries. Every entry in
MEMORY.mdshould carry a timestamp and a decay weight. Entries older than N days get flagged as potentially stale. Entries older than 2N days get reviewed automatically during compaction.Better cross-session rule enforcement. Style rules in
SOUL.mdneed a different mechanism than operational rules. One possible fix: a short verification pass at session start where the model confirms key rules by producing a brief sample that passes a rules-check before the session proceeds.Lower-cost dedup.
digest-state.jsonwith growing slug lists is functional but inefficient. A bloom filter or simple hash set would be more token-efficient at scale.
10. What This Means If You Are Building Agents
Five observations for anyone making product or architecture decisions here.
File-based memory has an underrated advantage: it is auditable. You can git diff your agent’s memory. You can read it. You can manually edit it. You can see exactly what the agent “knows” at any point in time. Black-box vector stores offer none of this. For high-stakes agent deployments where you need to explain or correct agent behavior, that auditability may be the deciding factor.
Memory architecture is a product decision, not an infrastructure footnote. The choice between “filing cabinet” and “Post-it note” affects what the system can do over weeks, not just sessions. That decision belongs in your product requirements, not in a ticket handed to a backend engineer after the fact.
The model quality floor is higher than most teams assume. File-based memory does not rescue a weak model. It gives a capable model better tools. Budget for the model tier that can actually use the memory correctly. If you’re cutting costs by running a smaller model on a complex memory architecture, you’ll get garbage output and blame the architecture.
The failure modes are predictable. Stale data. Rule fragility cross-session. Repetition without dedup. These are not random emergent behaviors. They follow from the architecture. Build for them from the start: memory decay, session verification passes, dedup state. The surprises are smaller if you’ve already designed for the known failure classes.
Proactivity must be engineered. Design your scheduling primitives from day one: cron schedules, heartbeat prompts, designed triggers. Reactive-only agents are useful but limited. The model will not spontaneously start checking things, sending digests, or doing background work. That scaffolding is your job.